
Monoliths aren’t necessarily bad, but in some cases, they don’t perform the job well enough. And no, autoscaling isn’t the only solution. You can have stateless monoliths running as a replicaset with HPA or even VPA (if you’re not stuck with JVM on fixed heap space) to achieve autoscaling. Taking that thought further, Kubernetes isn’t even necessary. You can perform autoscaling on VMs, although managing the spin-up and down times and IAC around it on VMs can be challenging. With that said, this post discusses what to do if you find yourself on a mission to break down a monolith into microservices. The most highly praised approach, the Strangler Application (inspired by the Strangler Fig application from Martin Fowler), is a great way to embark on this journey. There are plenty of blogs that explain the approach, so that’s not the reason why I’m typing away on a cool breezy evening in Bangalore with Arijit Singh’s songs in the background (no beer). This post describes an interesting strategy we implemented to refactor a powerful enterprise solution platform monolith into microservices while using the Strangler pattern. If you’re new to the pattern itself read here first.
A bit of background, and a shameless plug, this is our hands-on experience in moving to microservices at NimbleWork. Let’s explore how we utilized Choreography and CQRS as an implementation strategy to strangle an EJB-based monolith into microservices. This approach has enabled us to deliver new features more quickly and efficiently handle traffic bursts, such as when users log in to file timesheets or move cards to “done” on a Friday evening.
Choreography represents the communication between microservices through the publishing and subscribing of domain events. It differs from traditional messaging in that there is no two-way message sent/acknowledged flow. Instead, it follows a publish-and-subscribe model where downstream services decide whether to act upon the messages they receive. To understand this concept better, think of each microservice as a radio station broadcasting music on a specific FM frequency. If you want to listen to their music, you tune your radio to their frequency. The microservice doesn’t actively manage every connected client; it’s up to the client (in this case, the radio) to connect and respond to the received data.
In scenarios where you are employing the Database per Service pattern and a business transaction spans multiple services, relying on traditional models like the 2PC (two-phase commit) or messaging from the SOA era is not feasible. This is where choreography proves to be extremely useful. The diagram below illustrates this concept within a fictional e-commerce system, showcasing the handling of workflows when a customer signs up.
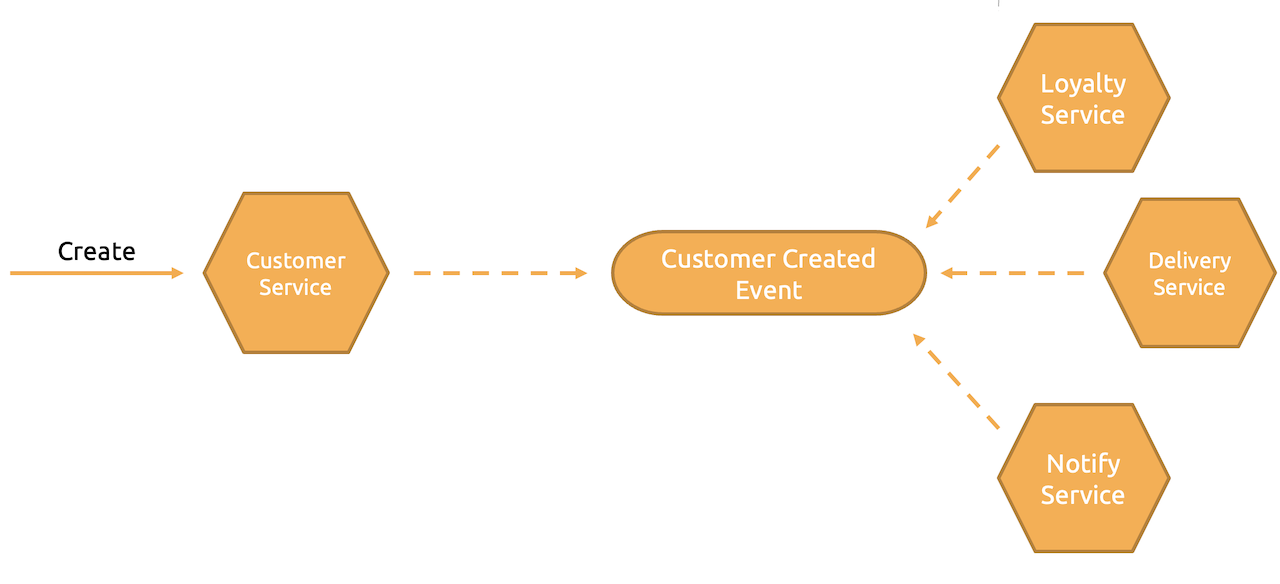
Here, the Loyalty, Delivery, and Notify services have tuned into a channel where the Customer Service publishes the Customer Created Event. It’s important to note that the Customer Service itself is unaware of who is listening to the messages.
Simply put, I introduce a spy into the monolith that tracks all activities within it. The implementation depends on the framework you are using. For example, with EJBs, you can easily create an EventListener that gets invoked after the creation, updating, or deletion of your business objects. This listener captures the business object and publishes corresponding events such as EntityCreated, EntityUpdated, and EntityDeleted. In Hibernate, you can use JPA Lifecycle Events, or in Spring Boot, you can use listeners on entity lifecycle methods. Regardless of your chosen approach, it’s crucial to execute these operations asynchronously to avoid keeping any threads tied to the transaction or the initiating request. The key is to ensure that these operations are quick and detached from the actual flow between layers in the application you’re refactoring. Now, you have a stream of events relaying your business objects or transactional data to an event broker (we prefer Kafka). From this point onwards, you have two options to consider, but let’s first understand CQRS before delving into those options.
CQRS, coined by Greg Young, stands for Command Query Responsibility Segregation, is a pattern closely aligned with Choreography. Querying data that spans multiple microservices when running microservices based on the Database per Service pattern or Choreography get challenging. This is where CQRS comes into play. In this approach, services that write data to their respective databases use Choreography to publish domain events, such as OrderCreated or NewSubscription in our e-commerce example. Downstream services then consume these events through event handlers to persist the data in a read-only database. This approach provides us with the flexibility to easily create multiple denormalized views of the data across various services. It also simplifies querying what would have been complex joins in a monolithic architecture.
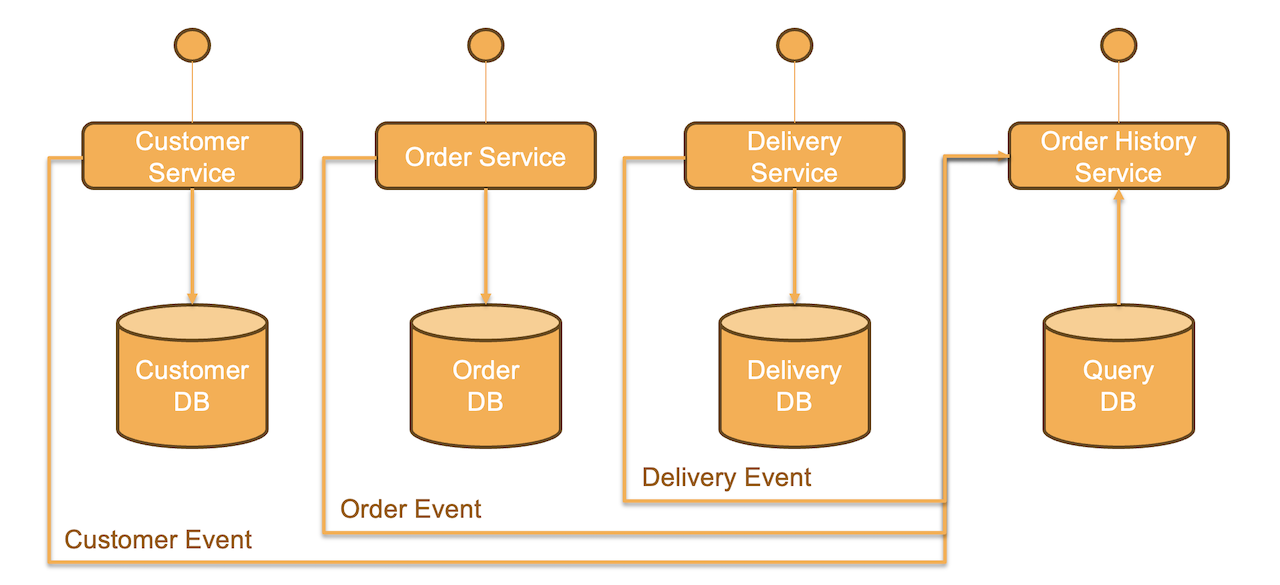
So, there you have it. On one side, the Monolith emits domain events, and a consumer at the other end of the event broker processes these domain events to save the business objects into other services’ data store. For example, we save them in MongoDB, which then serves as a backend for Reports and Analytics, Mobile Apps, and the Nimble Café. This approach offers multiple benefits. Firstly, it allows us to separate Read and Write databases in a system where reads outnumber writes, each of which can be tuned for their specific traffic patterns and transaction requirements. Another advantage is simplified transaction management, you can do away with fat transaction or transaction boundaries all-together and run thr writes on optimistic locking thereby increasing scalability. Lastly, we have moved a significant amount of traffic away from the monolith and into autoscaling microservices with this approach. This let’s us handle traffic better without impacting our Cloud Budget. MongoDB itself can be optimized for reads and has connectors to systems like Spark, Snowflake, and others, which can serve as a streaming backend for near real-time analytics or even AI. Essentially, I have now split my legacy system into two parts:
From here onwards, we continue extracting functionalities into one microservice at a time. All of these microservices read from the common read-only copy of the database while writing to their respective stores. Over time, the monolith keeps shrinking and reducing the number of domain events it fires as functionality moves out. But it doesn’t stop here. This broker also serves as the backbone for enabling choreography to the newer modules we’ve built on Microservices. More on Choreography and Saga will be discussed in a later post!
During the transition phase, the system operates on an eventual consistency model, and there are several factors to consider. What if your message broker goes down? What if the downstream service consuming messages is down? Will those messages be lost forever? What if a message is consumed from a broker but fails to persist into MongoDB? Building retries and utilizing Kubernetes-assisted restarts of failed services based on heartbeat monitors (Liveness And Readiness Probes) helps in outage scenarios. Similarly, incorporating retry logic in services before giving up and writing failed messages to a Dead Letter Queue proves to be beneficial. However, the most powerful technique in this case was using Upsert transactions in MongoDB. With this approach, a domain event that initially fails would eventually get inserted. If your system prioritizes availability and performance over consistency, this technique can work wonders, as it allows you to navigate through outages effectively.
The other aspect to consider is eventual consistency itself. If the cycle time for data written to the core product and saved in MongoDB is in seconds, it can lead to issues. Reports and feeds in the Café may start showing stale information. Therefore, it is crucial to ensure that the process is fast enough to complete before a user, in our case, browses to the reporting and analytics view or the Café feed after adding a card. Reactive programming, especially with Spring Boot’s added reactive extensions to Database, Messaging, Cloud, and Web modules, has proven to be a saviour in such cases.
Patterns provide a structured way to solve recurring design problems, or at least that’s how I see them. With sufficient reading and practising samples, one can grasp these patterns. However, the challenging part lies in improvising the translation of a pattern layout itself to achieve a technical or business strategy. This blog post cannot fully summarize the countless hours we have spent translating relational database schemas into NoSQL, all while ensuring it remains useful for other microservices that, in their initial phase, lift and shift the functionality. I’m not advocating that this approach is suitable for every Strangler Application, but the benefits we have gained from reaching this point have made the months of effort we put into getting the ES/CQRS backbone right worthwhile. I hope this helps fellow engineers who may encounter the same problem in the future.